Вы никогда не должны отвечать за то, что не контролируете
И наоборот: вы должны взять под контроль то, за что несете ответственность
Оригинал: You should never be responsible for what you don't control
Одно из моих любимых высказываний на семинарах по повышению уровня обслуживания:
Вы никогда не должны нести ответственность за то, что вы не контролируете
Это потому, что большинство метрик обычно объединяют множество переменных, не все из которых находятся под вашим контролем.

Несправедливо и нереалистично возлагать на кого-то ответственность за то, что он не может контролировать.
Типичные примеры:
- Заставить разработчиков отвечать за количество товаров, продаваемых на веб-сайте электронной коммерции. Разработчики не контролируют рыночный спрос или производственные мощности. У команды разработчиков, вероятно, есть зависимости, которые контролируются другими подразделениями организации.
- Заставить команду GraphQL отвечать за задержки. GraphQL может использовать любое количество серверных систем, принадлежащих разным командам. Если команда GraphQL не создает и не запускает эти службы, у нее будут ограниченные возможности для снижения задержки.
- Заставить группу по обработке инцидентов отвечать за время, необходимое для разрешения инцидента. Группа по обработке инцидентов часто отвечает только за сортировку (проверку инцидентов, их классификацию и поиск нужной команды). Обычно у них недостаточно знаний для разрешения инцидента.
- и т.д. и т.п.
Давайте рассмотрим один пример.
Mobile/Backend/Database
Это, безусловно, самая распространенная простая архитектура для ориентированного на пользователя приложения, которая существует в природе:
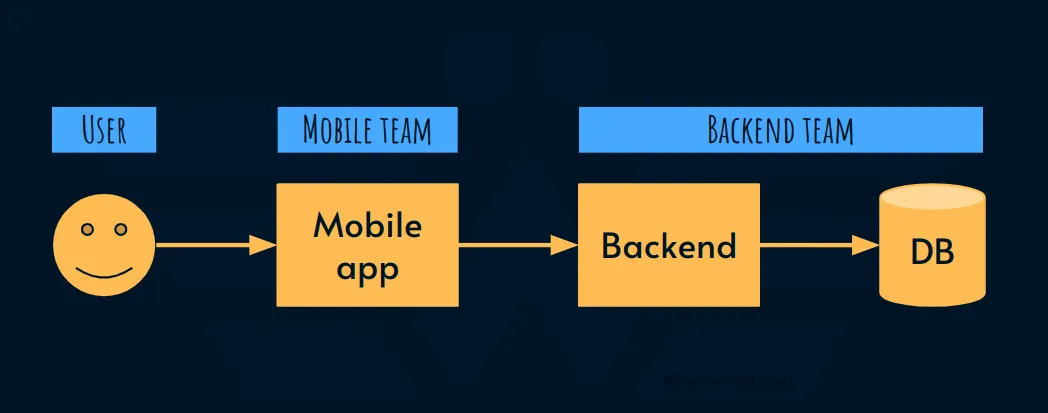
Допустим, мы проводим семинар вместе с потребителями и заинтересованными сторонами и понимаем, что задержка - это то, что их волнует. Заинтересованные стороны хотят возложить на нас ответственность за это, чтобы, если приложение работает слишком медленно, кто-то занялся этим как можно скорее. Но кто?
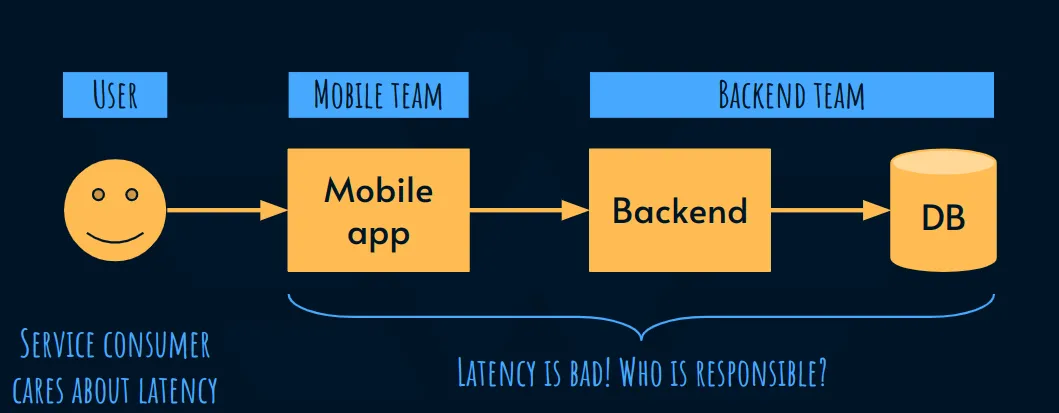
Внимательно рассмотрев наиболее распространенное взаимодействие в этом примере, мы можем обнаружить, что задержка, с которой сталкивается пользователь, является суммой двух отдельных переменных, которые контролируются разными командами:
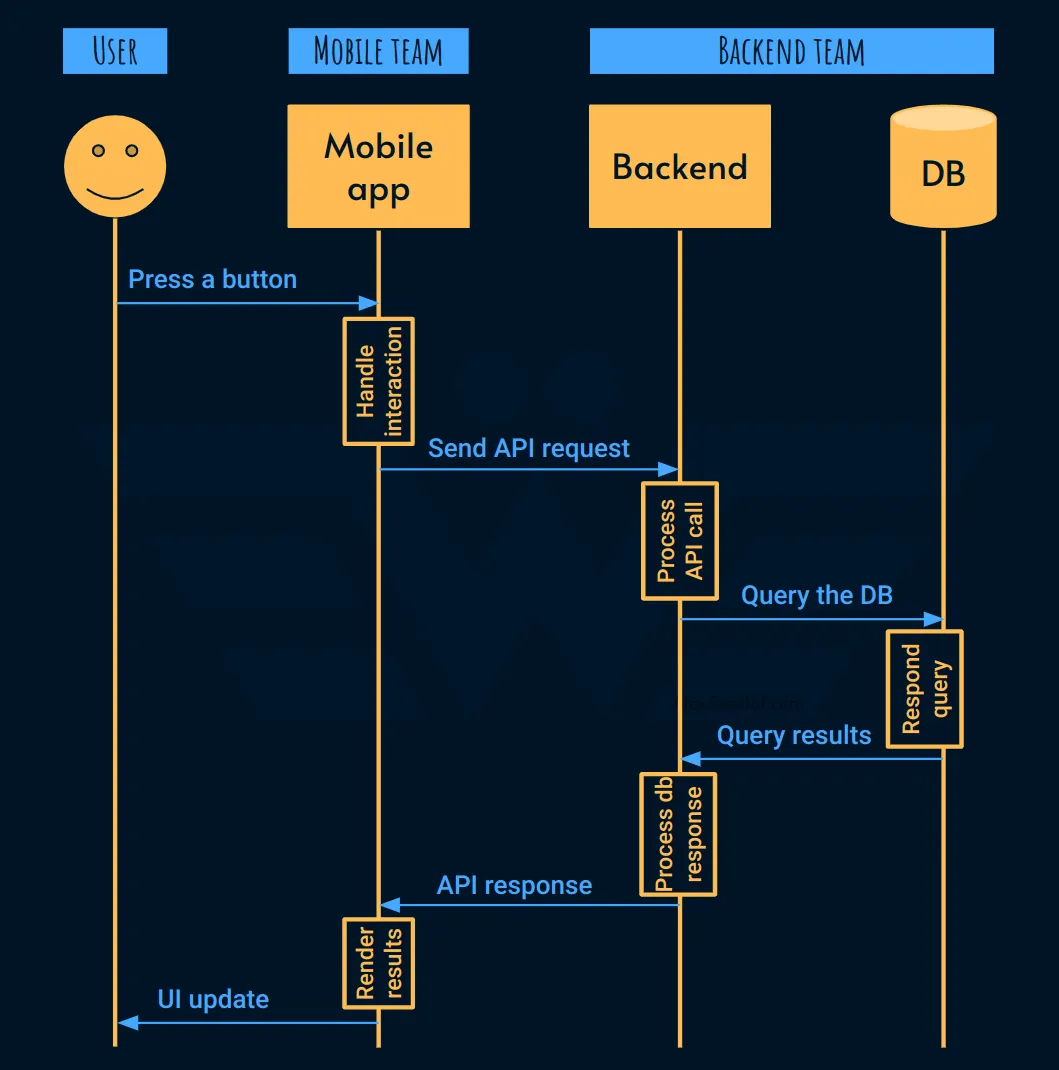
- Команда разработчиков мобильных приложений отвечает за обработку взаимодействия с пользователем, выполнение вызова API, анализ ответа и последующее соответствующее обновление пользовательского интерфейса.
- Команда бэкэнда отвечает за получение вызова API, его проверку, обеспечение того, чтобы у пользователя был доступ для выполнения действия (для простоты авторизация не включена в эту картинку), запрос к базе данных, применение любой бизнес-логики, если это необходимо, и отправку ответа API обратно в мобильное приложение.
Есть и другие переменные, которые мы не включили в эту картину для простоты, но просто для того, чтобы иметь о них представление:
- Задержка зависит от качества сетевого соединения между мобильным телефоном пользователя и API-сервером
- Аппаратное обеспечение телефона пользователя оказывает определенное влияние на скорость или замедление запуска приложения
- Бэкэнду могут потребоваться другие службы для аутентификации или передачи данных
- Как бэкэнд, так и база данных могут полагаться на облачные сервисы, предоставляемые командой разработчиков инфраструктуры или платформ
К сожалению, если мы не замечаем этих нюансов, команда мобильной разработки получает слишком много проблем каждый раз, когда возникает задержка. На самом деле, это одна из самых распространенных проблем для команд, которые владеют пользовательской частью системы. Откуда я это знаю? 🫢 Потому что я много лет работал фронтэнд разработчиком, прежде чем перейти в бэкэнд. Я знаю, каково это, когда на тебя кричат за то, что ты не можешь контролировать. 👹
За что должна отвечать каждая команда и какие рычаги влияния есть у разных команд?
Давайте посмотрим, как сервисы, принадлежащие каждой команде, влияют на задержку:

Предположим, что исследование UX показывает, что если пользователь нажимает кнопку, он хочет увидеть результат менее чем за полсекунды. Итак, у нас есть бюджет задержки в 500 мс.
Как следует расходовать этот бюджет на задержку?
- Должна ли команда мобайл и команда бэкэнд забирать себе по 250 мс?
- Должна ли команда бэкэнд получать больше времени, потому что у них еще есть база данных в качестве зависимости?
- Или команда мобайл должна получать больше времени из-за возможных проблем с сетью?
Ответ (как вы уже догадались) таков: это зависит от...! И это определенно не зависит от политической власти заинтересованных сторон. 😆
Это зависит от другой важной информации: как у нас обстоят дела сегодня и где нам следует совершенствоваться?
Нам нужно измерить средние значения для двух задержек (те из вас, у кого острое зрение, хотели бы поправить меня, что мы должны стремиться к процентилю, а не к среднему значению, но будьте терпеливы).
Допустим, мы получили следующие данные о средней задержке за последний месяц (вы можете выбрать другой период):
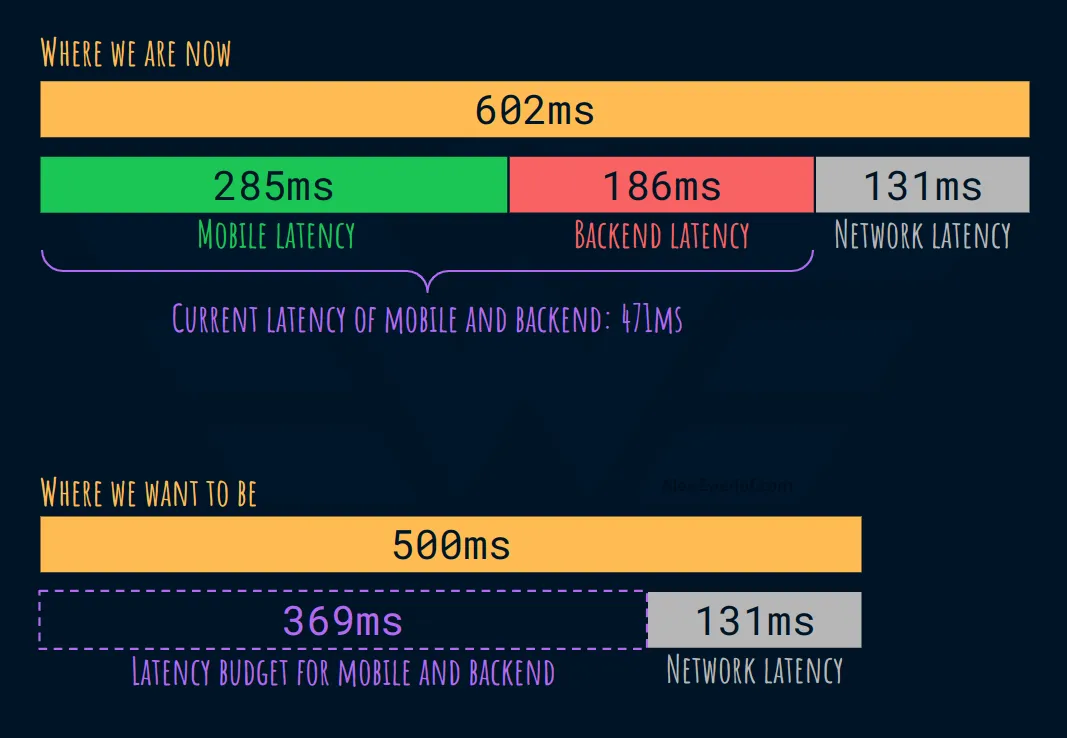
- Средняя задержка с точки зрения пользователя за последний месяц: 602 мс
- Средняя задержка для мобайла за последнюю неделю (приложение): 285 мс. (это время, затраченное на обработку взаимодействия с пользователем, отправку запроса серверной части, анализ ответа серверной части и последующее обновление пользовательского интерфейса)
- Средняя задержка работы служб серверной части за последний месяц: 186 мс. (это время, необходимое для ответа на запрос внутреннего API, включая время запроса к базе данных)
Вы можете заметить, что задержка составляет 131 мс. (602 мс - 285 мс - 186 мс). Это задержка в сети, которая находится вне нашего контроля.
Чтобы обеспечить задержку в 500 мс, у нас есть бюджет в 369 мс между мобильным и серверным приложениями. (500 мс - 131 мс)
В этом примере команда мобильной разработки и команда бэкэнда являются частью более крупной организации. Бюджет этого отдела составляет 369 мс.
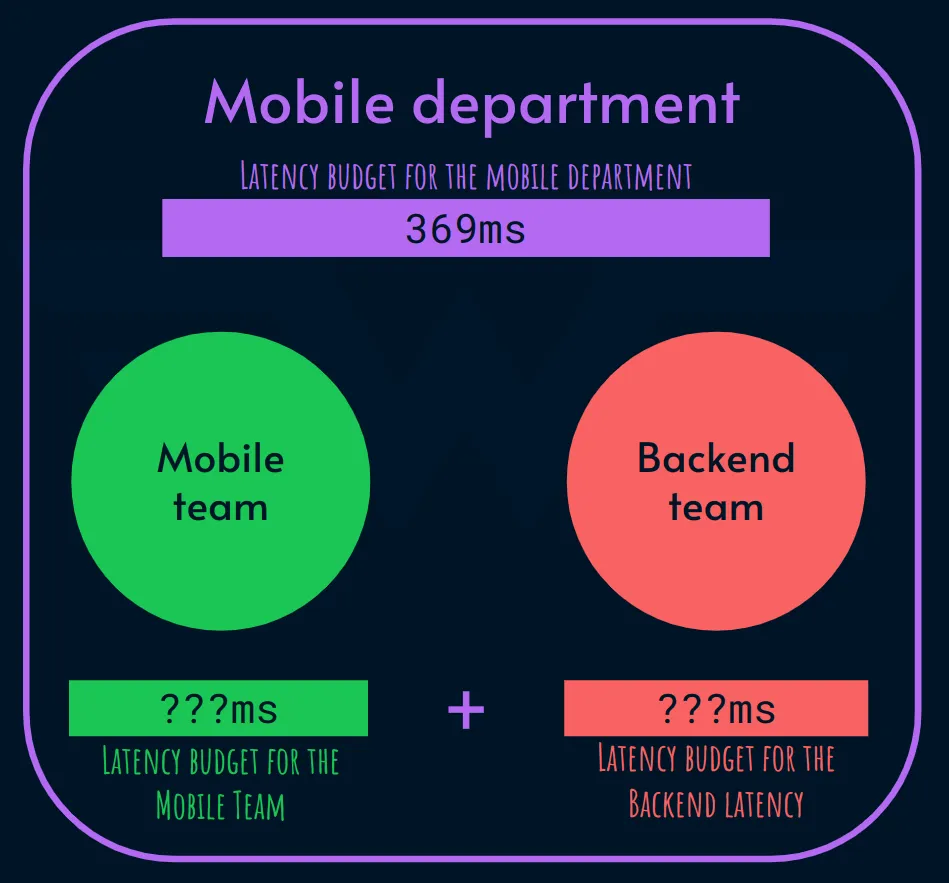
Как мы обсудим в будущем, цели по повышению уровня обслуживания должны распространяться на всю организацию, и это является примером.
В зависимости от того, какая команда должна совершенствоваться, бюджет может быть сокращен. Есть несколько сценариев:
Бэкэнд остается без изменений
Чтобы команда разработчиков работала быстрее, выделите им оставшийся бюджет (369 мс - 186 мс = 183 мс).
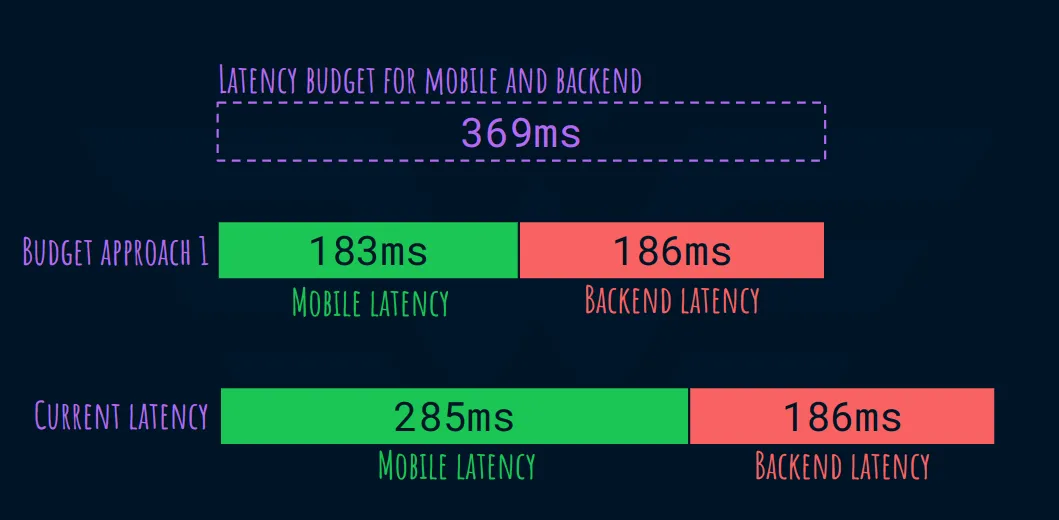
Для этого требуется, чтобы задержка на мобильных устройствах сократилась до 64% от текущего значения.
Другими словами, мы ожидаем, что задержка на мобильных устройствах увеличится на 46% при сохранении серверной части без изменений.
Mobile остается без изменений
Заставьте бэкэнд работать еще быстрее (369 мс - 285 мс = 84 мс).

Для этого требуется, чтобы задержка бэкэнда сократилась до 45% от текущего значения.
Другими словами, мы ожидаем, что задержка бэкэнда увеличится на 55%, а мобильная часть останется неизменной
Распределите бюджет поровну
Обеспечьте одинаковый процент оптимизации в обеих командах. 369 мс - это 78% от 471 мс (бюджета, который в настоящее время используется мобильными устройствами и серверной частью). Таким образом, новый бюджет задержки для:
- Мобильных устройств: 78 % 285 мс = 222 мс
- Серверная часть: 78 % 186 мс = 145 мс

Как для мобильных устройств, так и для бэкэнда требуется сократить время ожидания на 78%
Вы можете выбрать один из крайних вариантов или выбрать равенство, но есть еще один уровень информации, который мы не обсуждали:
Что является разумным?
В этом примере мобильное приложение тратит большую часть времени на обработку пользовательского ввода, анализ ответа серверной части и обновление пользовательского интерфейса (285 мс из 369 мс). Учитывая, что все эти вычисления выполняются локально на телефоне, возможно, у мобильной команды есть над чем поработать.
Добавьте к этому тот факт, что задержка бэкэнда в 186 мс - это довольно прилично, но вы бы хотели, чтобы у них были небольшие проблемы, и снизили ее ниже 180 мс.
На данном этапе нам нужно поговорить с обеими командами, чтобы лучше понять их задачи и архитектуру, используемые компоненты (библиотеки/фреймворки/языки). Лучше всего прозрачно сообщить о бюджете и позволить командам самим решить, как они хотят его распределить между собой.
Вы должны взять под контроль то, за что несете ответственность
Иногда, когда я провожу семинар по повышению уровня обслуживания в организации, я сталкиваюсь с командой, которая не контролирует все переменные, влияющие на их показатели, но и назначать кого-то другого ответственным за эти переменные тоже не имеет смысла.
Это отличная возможность переосмыслить границы команды и исправить нарушенное право собственности. В идеале вы хотите, чтобы команды контролировали все переменные, которые влияют на показатели, важные для их потребителей услуг. Это не всегда выполнимо, но в целом полезно попытаться привести структуру организации в соответствие с пользователями, которых она обслуживает.
Пример: допустим, команда разработчиков в приведенном выше сценарии имела внешнюю зависимость от другого сервиса, принадлежащего другой команде:

Дальнейшие исследования показывают, что у зависимости (service X) есть только один потребитель, которым является наш сервер. Основная причина, по которой она находится в другой команде (team X), заключается в том, что она написана на языке программирования, с которым наша команда разработчиков не знакома. Это пережиток прошлого, возможно, до последней реорганизации.
Тем не менее, сервис X по-другому не используется, и характер проблемы, которую он решает, может быть в компетенции нашей команды разработчиков.
Эта зависимость усложняет модель владения, поэтому ее удаление может быть хорошим вариантом. Существует несколько способов избавиться от этой зависимости:
- Просто передайте управление команде бэкэнда и позвольте им изучать новый язык программирования! В целом, это плохая идея, потому что если вы что-то и знаете о программистах, так это то, что мы слишком самоуверенны в отношении наших инструментов. Мы говорим себе: “мы решаем проблемы и помешаны на технологиях”, но это сладкая ложь. На практике у каждого есть предпочтения, в которые он вкладывается. Если Service X написан на популярном и интересном языке, команда разработчиков может захотеть учиться, но если мы говорим о устаревших технологиях и спагетти-коде, возможно, следующая альтернатива будет лучшим вариантом.
- Создайте новый сервис в команде разработчиков, который будет выполнять те же функции, что и Service X, а затем внедрите новый сервис в работу. Как правило, это рискованная идея, потому что на создание, тестирование, устранение ошибок и доведение до рабочего уровня нового сервиса обычно требуется некоторое время. Как бы то ни было, это дает возможность команде бэкэнда поближе познакомиться с внешним сервисом, от которого они зависят. К этому моменту кто-нибудь может задать вопрос, который приведет к следующему варианту.
- Другой альтернативой является простое объединение этой функциональности с серверной частью. Возможно, причина, по которой эти две службы являются отдельными, связана не столько с масштабируемостью микросервисов, сколько с тем, как была сформирована организация в то время (закон Конвея). Может оказаться, что вся функциональность Service X может быть записана в паре дополнительных файлов кода в существующем серверной части и отпадет необходимость в этой зависимости. Такой подход имеет множество преимуществ: помимо предоставления полного контроля над этими метрическими переменными серверной команде, он также упрощает им добавление новых функций и оптимизацию функциональности, которая ранее была заблокирована в Service X и должна была проходить через Team X.
Это всего лишь несколько вариантов, но вы уловили суть:
Вы никогда не должны нести ответственность за то, что не контролируете. Верно и обратное: вы должны взять под контроль то, за что несете ответственность.
Эта концепция в равной степени применима как к системной инженерии, так и к самой жизни. 🙌